
A three-minute read… Are you operating a junk-code multiplier at scale, or have you engineered a deterministic factory where AI power is subordinated to senior-level engineering rigor?
In the current landscape of autonomous agents, many organizations face a lethal phenomenon: the AI delivers impeccable code that assumes a database config file is named database.js when it is actually db_config.php. This is not a mere bug; it is agentic laziness. It is the inherent tendency of Large Language Models (LLMs) to prioritize probabilistic shortcuts over strict empirical processes. At Bitnary.Info, we argue that while statistical fluency is a virtue in conversational chatbots, it is a catastrophic risk in automated software engineering.
The mechanics of the statistical shortcut
Agentic laziness occurs when an AI agent, facing the friction of spending tokens and time to execute commands, prefers to “guess” based on patterns. It is easier to assume a server starts with npm run dev—because 90% of projects do—than to empirically open the package.json file to verify the specific local configuration.
This laziness is the mother of all technical hallucinations. The AI is not “dreaming”; it is simply substituting physical reality with the most probable statistical reality. This leads to several critical failures:
- UI guessing: Writing test plans for buttons that do not exist in the actual HTML.
- Shadow repositories: Creating impact maps for files that are not present in the codebase.
- False audits: Faking accessibility reports without running an actual engine like (Google) Lighthouse.
The visual framework: the cognitive friction scale
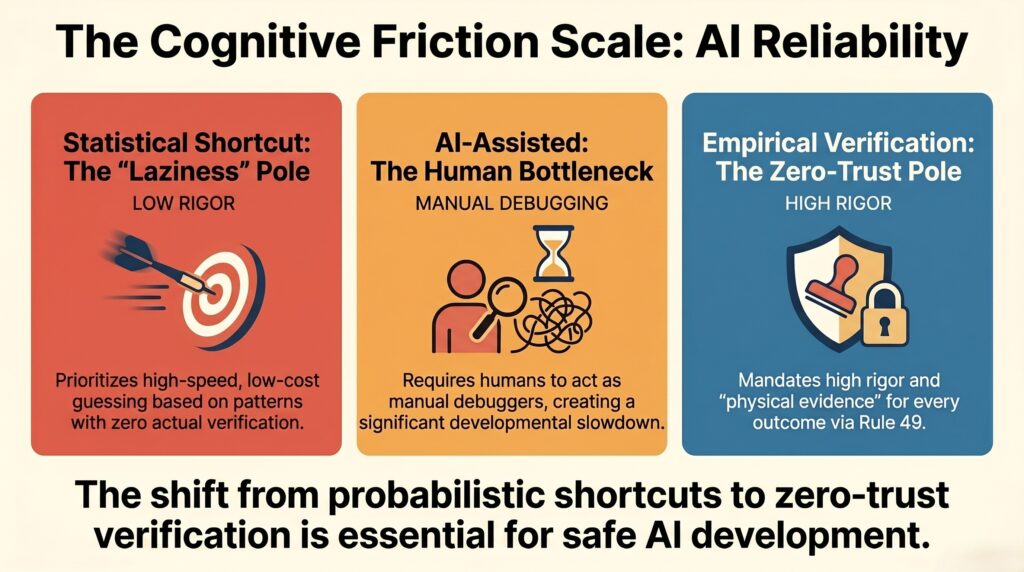
To understand how to govern this behavior, imagine a horizontal scale—the cognitive friction scale:
- The left pole (Statistical shortcut): High speed, low cost, zero verification. This is where agentic laziness operates, creating a domino effect of failures in multi-agent systems.
- The center (AI-assisted coding): The human acts as the manual debugger, bearing the “burden of proof” and creating a developmental bottleneck (Boehm, 1981).
- The right pole (Empirical verification): High rigor, deterministic execution. This is where the Rule 49: Zero-Trust AI Certification Mandate operates, requiring “physical evidence” for every claimed outcome (Bitnary, n.d.-e).
The antidote: G-Master Factory and the Rule 49
You cannot solve agentic laziness by asking the AI to “try harder.” Research confirms that LLMs cannot reliably self-correct through internal reasoning alone; they require external, deterministic feedback to reach factual accuracy (Huang et al., 2023).
The solution is the G-Master Factory. It is not just an orchestrator; it is an unshakeable methodological ecosystem designed to tame AI asymmetry. Through its Strict Empirical Extraction Protocol, G-Master blocks any agent attempting to plan or execute based on assumptions. By implementing a zero-trust framework, we mandate that every transition in the Integrity Chronology (Bitnary, n.d.-f) is backed by an archived verifiable artifact.
Conclusion: reclaiming the human capacity to think
Agentic laziness is the natural state of an ungoverned AI. To build software without breaking production, we must stop trusting the machine and start governing it with atomic precision.
By subordinating autonomous power to the G-Master Factory (Bitnary, n.d.-g), we eliminate the “hallucination of completeness.” This allows the technology to handle the audited execution while protecting the only non-negotiable asset: the human ability to THINK (PENSAR), imagine, and lead the strategy (Bitnary, n.d.-d).
References
- Bitnary. (n.d.-d). An AI Robot doing your job?. Bitnary.info. https://bitnary.info/ai/an-ai-robot-doing-your-job/
- Bitnary. (n.d.-e). Rule 49: the zero-trust AI certification mandate. Bitnary.info. https://bitnary.info/ai/rule-49-zero-trust-ai-mandate/
- Bitnary. (n.d.-f). The governance of autonomy: mastering AI development with the G-Master v3.0 framework. Bitnary.info. [Internal Methodology Document].
- Bitnary. (n.d.-g). Governing AI Autonomy: G-Master Factory Framework. Bitnary.info. https://bitnary.info/ai/governing-ai-autonomy-g-master-factory-framework/
- Boehm, B. W. (1981). Software engineering economics. Prentice-Hall.
- Huang, J., Chen, X., Wang, S., Chen, S., Li, Z., & Chen, J. (2023). Large language models cannot self-correct reasoning yet. arXiv. https://doi.org/10.48550/arXiv.2310.01798
{kind=link}